Übungen#
Für alle Übungsaufgaben verwenden wir den Datensatz
schlaf_gesundheit_lifestyle_datensatz.csv, der Informationen über
Schlafgewohnheiten und Lebensstil von 374 Personen enthält. Der Datensatz ist
eine deutsche Übersetzung des Datensatzes “Health and Sleep Relation” von
Kaggle.
Laden Sie ihn hier herunter: Download schlaf_gesundheit_lifestyle_datensatz.csv
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
# Datensatz einlesen
data = pd.read_csv('schlaf_gesundheit_lifestyle_datensatz.csv')
Übung 11.1: Streudiagramme
Laden Sie die Datei schlaf_gesundheit_lifestyle_datensatz.csv herunter.
Verschaffen Sie sich erst einen Überblick über die Daten mit
data.info()unddata.head().Erstellen Sie ein Streudiagramm, das die Beziehung zwischen Alter (x-Achse) und Schlafdauer (y-Achse) zeigt. Verwenden Sie blaue Kreise als Marker und beschriften Sie die Achsen: “Alter [Jahre]” und “Schlafdauer [Stunden]”. Titel: “Zusammenhang zwischen Alter und Schlafdauer”. Fügen Sie mit
plt.grid(True, alpha=0.3)Gitterlinien hinzu.Erstellen Sie ein zweites Streudiagramm, das die Beziehung zwischen Stresslevel (x-Achse) und Herzfrequenz (y-Achse) zeigt. Verwenden Sie rote Dreiecke als Marker (marker=‘^’). Beschriften Sie die Achsen entsprechend und setzen Sie einen aussagekräftigen Titel.
Lösung
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib.style as style
style.use('seaborn-v0_8')
import numpy as np
# Datensatz einlesen
data = pd.read_csv('schlaf_gesundheit_lifestyle_datensatz.csv')
# 1. Überblick über die Daten
print(data.info())
print(data.head())
# 2. Streudiagramm: Alter vs. Schlafdauer
plt.figure()
plt.scatter(data['Alter'], data['Schlafdauer'])
plt.xlabel('Alter [Jahre]')
plt.ylabel('Schlafdauer [Stunden]')
plt.title('Zusammenhang zwischen Alter und Schlafdauer')
plt.grid(True, alpha=0.3)
plt.show()
# 3. Streudiagramm: Stresslevel vs. Herzfrequenz
plt.figure()
plt.scatter(data['Stresslevel'], data['Herzfrequenz'], color='red', marker='^')
plt.xlabel('Stresslevel')
plt.ylabel('Herzfrequenz [Schläge/min]')
plt.title('Zusammenhang zwischen Stress und Herzfrequenz')
plt.grid(True, alpha=0.3)
plt.show()
Übung 11.2: Balkendiagramme und Histogramme
Erstellen Sie ein Balkendiagramm für eine Auswahl von 5 Personen aus dem Datensatz. Filtern Sie die ersten 5 Zeilen mit
data.head(5)und stellen Sie deren Alter auf der x-Achse und Schlafdauer auf der y-Achse dar. Verwenden Sie verschiedene Farben, drehen Sie die x-Achsenbeschriftung um 45° und setzen Sie den Titel “Schlafdauer der ersten 5 Personen”.Erstellen Sie ein Histogramm der Schlafdauer aus dem Datensatz mit 15 Bins, Transparenz (alpha=0.7), grüner Farbe mit schwarzen Rändern. Berechnen Sie den Durchschnitt der Schlafdauer mit
data['Schlafdauer'].mean()und fügen Sie eine vertikale Linie für diesen Durchschnittswert hinzu. Erstellen Sie eine Legende, die den Durchschnittswert anzeigt.
Lösung
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
data = pd.read_csv('schlaf_gesundheit_lifestyle_datensatz.csv')
# 1. Balkendiagramm: Erste 5 Personen
personen = data.head(5)
plt.figure()
plt.bar(range(5), personen['Schlafdauer'])
plt.xlabel('Person')
plt.ylabel('Schlafdauer [Stunden]')
plt.title('Schlafdauer der ersten 5 Personen')
plt.xticks(range(5), personen['Person_ID'])
plt.tight_layout()
plt.show()
# 2. Histogramm: Schlafdauer
durchschnitt_schlafdauer = data['Schlafdauer'].mean()
plt.figure()
plt.hist(data['Schlafdauer'], bins=15, alpha=0.7, color='green', edgecolor='black')
plt.axvline(durchschnitt_schlafdauer, color='red', linestyle='--', linewidth=2,
label=f'Durchschnitt: {durchschnitt_schlafdauer:.1f}h')
plt.xlabel('Schlafdauer [Stunden]')
plt.ylabel('Häufigkeit')
plt.title('Verteilung der Schlafdauer')
plt.legend()
plt.grid(True, alpha=0.3)
plt.show()
Übung 11.3 Subplots
Analysieren Sie die durchschnittliche Schlafqualität nach Berufsgruppen.
Berechnen Sie die durchschnittliche Schlafqualität pro Beruf.
Erstellen Sie ein horizontales Balkendiagramm (
plt.barh) und sortieren Sie die Berufe nach Schlafqualität (bester zuerst).Fügen Sie eine horizontale Linie für den Gesamtdurchschnitt hinzu.
Verwenden Sie ein professionelles Styling-Theme (
plt.style.use('seaborn-v0_8')).Titel: “Durchschnittliche Schlafqualität nach Beruf”.
Lösung
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
data = pd.read_csv('schlaf_gesundheit_lifestyle_datensatz.csv')
# Professionelles Styling
plt.style.use('seaborn-v0_8')
# 1. Filtere Daten für 5 verschiedene Berufe
arzt_data = data[data['Beruf'] == 'Arzt']
lehrer_data = data[data['Beruf'] == 'Lehrer']
manager_data = data[data['Beruf'] == 'Manager']
ingenieur_data = data[data['Beruf'] == 'Ingenieur']
anwalt_data = data[data['Beruf'] == 'Anwalt']
# 2. Berechne Durchschnitte manuell
berufe = ['Arzt', 'Lehrer', 'Manager', 'Ingenieur', 'Anwalt']
durchschnitte = [
arzt_data['Schlafqualitaet'].mean(),
lehrer_data['Schlafqualitaet'].mean(),
manager_data['Schlafqualitaet'].mean(),
ingenieur_data['Schlafqualitaet'].mean(),
anwalt_data['Schlafqualitaet'].mean()
]
print(durchschnitte)
# 3. Gesamtdurchschnitt berechnen
gesamtdurchschnitt = data['Schlafqualitaet'].mean()
# 4. Balkendiagramm
plt.figure()
plt.bar(berufe, durchschnitte)
# Horizontale Linie für Gesamtdurchschnitt
plt.axhline(gesamtdurchschnitt, color='red', linestyle='--', linewidth=2,
label=f'Gesamtdurchschnitt: {gesamtdurchschnitt:.1f}')
plt.xlabel('Durchschnittliche Schlafqualität (1-10)')
plt.ylabel('Beruf')
plt.title('Durchschnittliche Schlafqualität nach Beruf')
plt.legend()
plt.grid(True, alpha=0.3, axis='x')
plt.tight_layout()
plt.show()
Übung 11.4: Dashboard für Schlafanalyse
Erstellen Sie ein 2x2 Subplot-Dashboard mit folgenden Visualisierungen:
Subplot 1 (oben links): Histogramm der Schlafdauer für alle Personen
Subplot 2 (oben rechts): Streudiagramm Stresslevel vs. Schlafqualität
Subplot 3 (unten links): Balkendiagramm der Herzfrequenz für die ersten 6 Personen
Subplot 4 (unten rechts): Streudiagramm Alter vs. Aktivitätslevel
Zusätzliche Anforderungen:
Figur-Größe: 15x12 Zoll
Gemeinsamer Haupttitel: “Schlaf- und Gesundheitsdashboard”
Lösung
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
data = pd.read_csv('schlaf_gesundheit_lifestyle_datensatz.csv')
# 2x2 Subplot-Layout erstellen
fig, axes = plt.subplots(2, 2, figsize=(15, 12))
# Subplot 1: Histogramm der Schlafdauer
axes[0, 0].hist(data['Schlafdauer'], bins=15, alpha=0.7, color='blue', edgecolor='black')
axes[0, 0].set_xlabel('Schlafdauer [h]')
axes[0, 0].set_ylabel('Häufigkeit')
axes[0, 0].set_title('Verteilung der Schlafdauer')
axes[0, 0].grid(True, alpha=0.3)
# Subplot 2: Streudiagramm Stresslevel vs. Schlafqualität
axes[0, 1].scatter(data['Stresslevel'], data['Schlafqualitaet'], alpha=0.6, color='red')
axes[0, 1].set_xlabel('Stresslevel')
axes[0, 1].set_ylabel('Schlafqualität')
axes[0, 1].set_title('Stress vs. Schlafqualität')
axes[0, 1].grid(True, alpha=0.3)
# Subplot 3: Balkendiagramm Herzfrequenz (erste 6 Personen)
erste_6 = data.head(6)
farben = ['blue', 'orange', 'green', 'red', 'purple', 'brown']
axes[1, 0].bar(range(len(erste_6)), erste_6['Herzfrequenz'], color=farben, alpha=0.8)
axes[1, 0].set_xlabel('Person')
axes[1, 0].set_ylabel('Herzfrequenz [Schläge/min]')
axes[1, 0].set_title('Herzfrequenz (erste 6 Personen)')
axes[1, 0].set_xticks(range(len(erste_6)))
axes[1, 0].set_xticklabels([f'P{i+1}' for i in range(len(erste_6))])
axes[1, 0].grid(True, alpha=0.3)
# Subplot 4: Streudiagramm Alter vs. Aktivitätslevel
axes[1, 1].scatter(data['Alter'], data['Aktivitaetslevel'], alpha=0.6, color='green')
axes[1, 1].set_xlabel('Alter [Jahre]')
axes[1, 1].set_ylabel('Aktivitätslevel')
axes[1, 1].set_title('Alter vs. Aktivitätslevel')
axes[1, 1].grid(True, alpha=0.3)
plt.suptitle('Schlaf- und Gesundheitsdashboard', fontsize=16, fontweight='bold')
plt.tight_layout()
plt.show()
Übung 11.5: Random Walk
Teilaufgabe 1:
Programmieren Sie eine Funktion, die einen Random Walk mit dem Turtle-Modul implementiert (siehe Übung 7.5). Der Roboter soll 100x zufällig eine Richtung Osten, Süden, Westen oder Norden wählen und dann 10 Schritte laufen. Lassen Sie dann den Abstand zum Ursprung berechnen und von der Funktion zurückgeben.
Tipp: Die aktuelle Position des Roboters kann mit der Methode .position()
bestimmt werden. Die Anweisung x,y = robo.position() speichert die x-Position
in x und entsprechend die y-Position in y, wenn Ihr Roboter robo heißt.
Teilaufgabe 2:
Lassen Sie nun den Roboter 10 x seinen Random Walk ausführen und jeweils die Entfernung zum Ursprung zurückgeben. Sammeln Sie die Entfernungen in einer Liste. Untersuchen Sie mit einem Histogramm, wie die Entfernungen verteilt sind. Wenn die Rechenzeiten auf Ihrer Hardware annehmbar sind, erhöhen Sie bitte die Anzahl der Random Walks (vorsichtig!).
Tipp: Setzen Sie innerhalb der Random-Walk-Funktion die Geschwindigkeit des
Roboters auf 0, also robo.speed(0), falls Ihr Roboter robo heißt. Fügen
Sie außerdem nach der letzten Bewegung den Befehl robo.done()ein. Dann wird
die Bewegung nicht mehr animiert und nur der Laufweg angezeigt.
Lösung
Teilaufgabe 1: Implementierung eines Random Walks als Funktion
import ColabTurtlePlus.Turtle as turtle
import numpy as np
def random_walk():
robo = turtle.Turtle()
robo.speed(0)
for i in range(100):
zufallswinkel = np.random.randint(3) * 90
robo.left(zufallswinkel)
robo.forward(10)
x,y = robo.position()
robo.done()
entfernung = np.sqrt(x**2 + y**2)
return entfernung
Teilaufgabe 2: Durchführung von vielen Random Walks und Sammeln der Entfernungen in einer Liste (hier 500 Randon Walks):
turtle.clearscreen()
liste_entfernungen = []
for i in range(500):
d = random_walk()
liste_entfernungen.append(d)
Das Ergebnis könnte beispielhaft so aussehen:
Fig. 16 Endergebnis von 500 Random Walks#
Der Code zur Erzeugung des Histogramms ist:
import matplotlib.pyplot as plt
plt.figure()
plt.hist(liste_entfernungen, bins=25)
plt.xlabel('Entfernung zum Ursprung in px')
plt.ylabel('Häufigkeit')
plt.title('Analyse der Random Walks');
Das Histogramm könnte beispielhaft so aussehen:
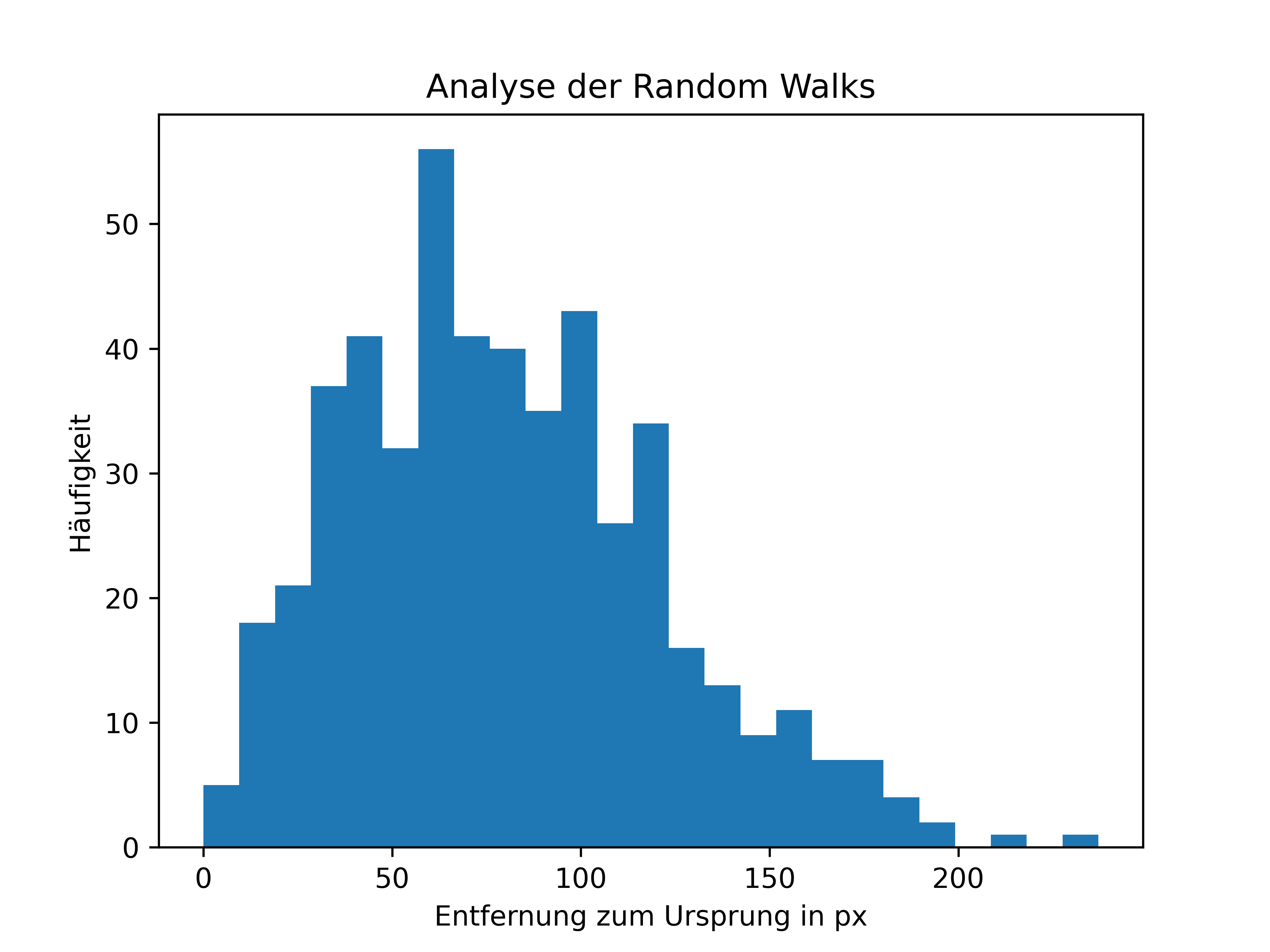
Fig. 17 Histogramm der 500 Random Walks#
Die Entfernungen sind nicht gleichverteilt und auch nicht normalverteilt.